Im ersten Blog habe ich einen praktischen Anwendungsfall für Maschine Learning eingeführt und eine grobe Lösung skizziert. Im zweiten Teil habe ich die mathematischen Hintergründe des Algorithmus erläutert. Und in diesem dritten Teil möchte ich nun eine konkrete Implementation in Java zeigen. Dazu nutzen wir wie im ersten Teil bereits erläutert die Java-Library von Weka für den Algorithmus. Das hier gezeigte Beispiel ist auch komplett auf Github zu finden.
Den Anwendungsfall, den ich hier als Beispiel verwende grob zusammengefasst:
Ich habe laufend Zahlungen denen ich gerne den jeweiligen Budgetposten für mein Budget zuweisen möchte. Da sich meine Zahlungen laufend verändern, brauche ich eine Lösung, die sich ebenfalls laufend verbessert und sich den neuen Gegebenheiten anpasst. Als Lösung bietet sich ein Bayes-Algorithmus basierend auf Vektoren an. Dieser wird auch für andere Anwendungen wie beispielsweise die Spamerkennung in E-Mails verwendet.
Ich definiere aus jeder meiner Zahlungen einen entsprechenden Vektor. Danach suche ich, anhand früherer Vektoren, den Budgetposten, der am besten, bzw mit grösster Wahrscheinlichkeit zu meiner Zahlung passt. Wie bereits erwähnt, habe ich den Ablauf und den Anwendungsfall in den zwei vorangegangenen Blogposts bereits etwas detaillierter erläutert.
Die Implementation ist ganz grob in 5 Schritte aufgeteilt:
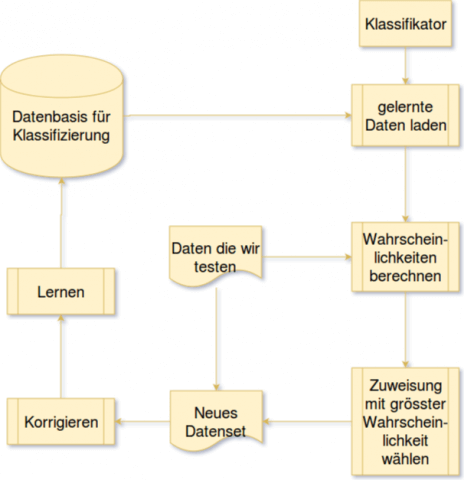
- Klassifikator laden und aus den früheren Daten (Zahlungen mit Budgetposten) lernen
- Die Wahrscheinlichkeiten für den neuen Datensatz (Zahlung) berechnen
- Auswahl der Budgetposition mit der grössten Wahrscheinlichkeit
- Falls nötig Korrektur der Zuweisung des Budgetpostens durch den Benutzer
- Lernen der neuen Zuweisung und Speichern dieser in der Datenbasis
Nachfolgend zeige ich, wie ich die 5 Schritte in Java implementiert habe.
Aufbau der Lösung
Weil ich im gesamten Ablauf immer mit denselben Vektor verwendet habe, habe ich die Definition des Vektors in eine eigene Methode ausgelagert:
private static Instances createFeatureVector() {
ArrayList attribute = new ArrayList(5);
ArrayList weekday = new ArrayList();
weekday.add("Montag");
weekday.add("Dienstag");
weekday.add("Mittwoch");
...
attribute.add(new Attribute("Wochentag", weekday));
ArrayList store = new ArrayList();
store.add("Lebensmittel");
store.add("Moebel");
store.add("Gesundheit");
...
attribute.add(new Attribute("Geschäft", store));
ArrayList amount = new ArrayList();
amount.add("mikro");
amount.add("klein");
amount.add("mittel");
...
attribute.add(new Attribute("Betrag", amount));
ArrayList classVal = getBudgetPositions();
attribute.add(new Attribute("Klasse", classVal));
Instances featureVectorDefinition = new Instances("TestInstance", attribute, 0);
return featureVectorDefinition;
}
und auch die Definition der verschiedenen Budgetpositionen habe ich in eine Methode ausgelagert.
private static ArrayList getBudgetPositions() {
ArrayList classVal = new ArrayList();
classVal.add("Nahrungsmittel");
classVal.add("Persönliche Ausgaben");
classVal.add("Hobby");
...
return classVal;
}
So kann ich beide Teile für alle weiteren Schritte über diese Methoden beziehen. Wenn ich mein Beispiel erweitern will, muss ich die Definition nur an diesen zwei Stellen erweitern. Die eigentliche Implementation der Logik folgt in den nächsten Abschnitten:
Klassifikator laden und aus den früheren Daten (Zahlungen mit Budgetposten) lernen
In einem ersten Schritt müssen wir unseren Klassifikator instantiieren. In diesem Beispiel verwenden wir einen naiven bayesianischen Klassifikator. Diesen erstellen wir durch die Verwendung von WEKA mittels folgender Zeilen:
import weka.classifiers.bayes.NaiveBayes; ... NaiveBayes naivebayes = new NaiveBayes(); naivebayes.buildClassifier(trainingsSet);
Dem Klassifikator geben wir als Input (buildClassifier Methode) ein Objekt vom Typ Instances mit, welches die früher gelernten Zuweisungen von Zahlungen und Budgetpositionen enthält.
Die bereits gelernten Zuweisungen sind in einem .arff File gespeichert und haben folgende Struktur:
@relation Rel
@attribute Wochentag {Montag,Dienstag,Mittwoch,Donnerstag,Freitag,Wochenende}
@attribute Geschaeftszweig {Lebensmittel,Moebel,Gesundheit,Verkehr,Mobilfunk,Radio,Energie,Versicherungen,Steuern,Bankomat,Andere}
@attribute Betrag {mikro,klein,mittel,gross,riesig}
@attribute Klasse {Nahrungsmittel, ‚Persönliche Ausgaben‘, Hobby, Freizeit, Gesundheitskosten, Bekleidung, Arzt, Reserve, Miete, Steuern, Krankenkasse}@data
Dienstag,Lebensmittel,klein,Nahrungsmittel
Dienstag,Moebel,gross,Freizeit
Den Inhalt des arff-File kann direkt aus dem File-System in ein Instances Objekt umgewandelt werden. Die Instances können mittels getDataSet Methode auf einem DataSource Objekt geholt werden:
private static Instances loadTrainingsSet() {
DataSource source;
source = new DataSource("learned_budget.arff");
Instances data = source.getDataSet();
data.setClassIndex(data.numAttributes() - 1);
return data;
}
Im Beispiel habe ich das Auslesen der Trainingsdaten in eine eigene Methode ausgelagert, da wir die Daten auch bei einem späteren Schritt brauchen. Nun haben wir einen trainierten Bayes Klassifikator den wir für die weiteren Berechnungen verwenden können.
Die Wahrscheinlichkeiten für den neuen Datensatz (Zahlung) berechnen
In einem nächsten Schritt will ich meine Zahlung hinsichtlich Zugehörigkeit zu Budgetposten analysieren. Dazu muss ich zuerst die Zahlung in einen entsprechenden Vektor umwandeln (Instances Objekt). Auch diesen Schritt habe ich für eine bessere Übersichtlichkeit in eine Methode ausgelagert. Die Definition der Zahlung kann dabei mittels Array übergeben werden. In meinem Beispiel gebe ich daher nur an welchen Array-Key mein jeweiliger Attributwert hat.
Instances testData = defineTestdata(featureVector);
testData.setClassIndex(trainingsSet.numAttributes() - 1);
...
private static Instances defineTestdata(Instances testData) {
double[] instanceValue1 = new double[testData.numAttributes() - 1];
instanceValue1[0] = 1; // Dienstag
instanceValue1[1] = 0; // Lebensmittel
instanceValue1[2] = 1; // klein
testData.add(new DenseInstance(1.0, instanceValue1));
return testData;
}
In einer praktischen Anwendung muss die Zahlung noch auf die entsprechenden Attribut-Werte umgewandelt werden. Auch hier gibt es natürlich wieder verschiedenste Arten wie ich z.B. aus meinem Zahlungstext lesen kann, um welche Art Geschäft es sich handelt, etc. Ich lasse das hier bewusst weg, da dies schon fast einen eigenen Blogpost füllen würde.
Die Berechnung der Wahrscheinlichkeiten pro Budgetposten erledigt Weka für mich. Ich übergebe dazu unseren Zahlungsdaten-Vektor an den Klassifikator und erhalte ein Array mit den Wahrscheinlichkeiten pro Budgetposten zurück.
double[] probability = naivebayes.distributionForInstance(testData.firstInstance());
Alle möglichen Methoden, die uns die Implementation des naiven Bayes Klassifikators in Weka bieten, finden wir in der Dokumentation.
Auswahl der Budgetposition mit der grössten Wahrscheinlichkeit
Um herauszufinden, welcher Budgetposten vom System vorgeschlagen werden soll, fehlt nur noch ein letzter Schritt. Es muss noch gewählt werden, bei welchem Budgetposten die grösste Wahrscheinlichkeit berechnet wurde.
double[] probability
Da wir als Resultat ein Array mit den berechneten Wahrscheinlichkeiten erhalten, müssen wir dieses nur noch in Verbindung mit den Bezeichnungen der Budgetposten bringen und nach Grösse der Wahrscheinlichkeit sortieren. Ich habe mich entschieden, dies mit einer HashMap zu lösen und diese in einem for-Loop zu befüllen. Um schlussendlich mit der Methode Collections.max den grössten Wert zu ermitteln.
HashMap budgetmap = new LinkedHashMap();
ArrayList budgetPositions = getBudgetPositions();
for (int i = 0; i < budgetPositions.size(); i++) {
budgetmap.put(probability[i], budgetPositions.get(i));
}
double maxValueInMap = Collections.max(budgetmap.keySet());
int budgetpositionindex = budgetPositions.indexOf(budgetmap.get(maxValueInMap));
In einer praktischen Anwendung müsste das ermittelte Resultat zu diesem Zeitpunkt noch dem Benutzer zur Überprüfung anzeigen. Erst durch diesen Schritt hat der Benutzer die Möglichkeit die Resultate seinen Bedürfnissen und Vorlieben entsprechend anpassen. Die vom Benutzer angepassten oder belassenen Resultate sollen nun in einem letzten Schritt wieder zu unserem Trainingsset hinzugefügt werden, sodass bei der nächsten Klassifizierung die neuen Erkenntnisse ebenfalls berücksichtigt werden. Der Einfachheit halber lasse ich aber auch hier die Implementation der Benutzerauswahl weg.

Lernen der neuen Zuweisung und Speichern dieser in der Datenbasis
Als letzten Punkt in unserem Ablauf wollen wir den berechneten und vom Benutzer überprüften Vektor in unserer Trainingsdaten übernehmen. Auch diesen Schritt habe ich wiederum in eine eigene Methode ausgelagert.
learnNewTrainingData(budgetpositionindex);
...
private static void learnNewTrainingData(int learnedclass) throws Exception {
Instances testdata = defineTestdata(createFeatureVector());
Instances trainingsSet = loadTrainingsSet();
Instance newdataset = testdata.get(0);
double[] instanceValue1 = newdataset.toDoubleArray();
double[] instanceValue = Arrays.copyOf(instanceValue1, instanceValue1.length + 1);
instanceValue[3] = learnedclass;
trainingsSet.add(new DenseInstance(1.0, instanceValue));
BufferedWriter writer = new BufferedWriter(new FileWriter("learned_budget.arff"));
writer.write(trainingsSet.toString());
writer.flush();
writer.close();
}
Optimierungsmöglichkeiten
Beim oben gezeigten Ablauf handelt es sich um eine relativ einfache Implementation einer Lösung. Durch den Einsatz angepasster Formen des Algorithmus, beispielsweise Bayes’sche Netze können die Resultate weiter optimiert werden. Ebenfalls stark beeinflusst werden die Resultate durch die Auswahl der definierten Attribute der Zahlungen. Je nach Anwendungsfalls kann anhand einer Testserie eine optimale Implementation gefunden werden.
Die grafischen Tools von Weka unterstützen bei der Suche nach der idealen Lösung ebenfalls.
Ich wünsche euch viel Vergnügen bei euren ersten Schritten mit einem Machine Learning Ansatz mittels Weka und Bayes Klassifikation.
Hier den zweiten Teil der Blogpostserie lesen.
Hier den ersten Teil der Blogpostserie lesen.