Wenn wir bei Puzzle vom Jagen mittels Jaeger und OpenTracing sprechen, hat das nicht viel mit dem eigentlichen Jagen oder gar dem Puzzle
„Ein Jäger auf einer Reise“ zu tun. Stattdessen sind wir in unserer verteilten Architektur auf der Suche nach einem Fehler.

In einer verteilten Architektur ist das Analysieren und Auffinden eines Fehlers häufig schwieriger, als dies bei einer nicht verteilten Architektur der Fall ist.
Nehmen wir als Beispiel die Bestellung eines Artikels in einem Online Shop. In einer klassischen, monolithischen Architektur wird der Bestellprozess von einer einzelnen Applikation abgearbeitet. Alle Informationen der durchgeführten Schritte finden sich im Applikationslog dieser einen Applikation, sofern der Entwickler genügend Log Nachrichten vorgesehen hat. In einer verteilten Architektur hingegen durchläuft der Bestellprozess mehrere kleine Teilapplikationen, bis er schlussendlich erfolgreich abgeschlossen ist.
Nun gibt es Systeme, wie zum Beispiel Fluentd, welche die Logs aller verteilten Applikationen sammeln, aggregieren und in einem globalen Suchindex abspeichern und diese dem Entwickler zur Verfügung stellen. Dies mag das Problem zum Teil entschärfen und gibt dem Bug-Hunter die Möglichkeit, zumindest den Ablauf des Bestellprozesses nachvollziehen zu können. Jedoch fehlen dem Fehlersuchenden meist noch zusätzliche Informationen, wie zum Beispiel die Zeit, welches jedes Teilsystem für die Verarbeitung benötigte, oder auch Detailinformationen zum abgearbeiteten Prozess.
Auf der Suche nach Fehlern
Man ahnt es schon, hier kommt Jaeger ins Spiel. Mit Jaeger lassen sich genau solche Informationen, wie die Zeit eines Subprozesses, auswerten und noch vieles mehr. Für unsere Lösung Lagoon nutzen wir Jaeger schon seit dem Start des Projekts mit hoher Zufriedenheit. Verschiedene Bottlenecks und Fehler konnten so bereits während der Entwicklung gefunden und behoben werden.
Anhand eines Beispiels zeigen wir dir nun, wie Jaeger helfen kann, Fehler schneller zu finden und einzugrenzen.
Bevor wir aber in die Tiefen von Jaeger eintauchen, müssen wir kurz erläutern was mit einem Span und Trace gemeint ist. Jaeger implementiert die OpenTracing Specification. Darin wird ein Span oder zu Deutsch ein Bereich als Arbeitspaket definiert. Dieses Arbeitspaket beinhaltet einen Namen, eine Startzeit sowie die Dauer des entsprechenden Pakets. Durch Verschachtelung lassen sich so Beziehungen zwischen verschiedenen Paketen modellieren. In unserem erwähnten Online Shop wäre ein einzelner Span zum Beispiel die Suche nach einem Artikel und dessen Verfügbarkeit in der Datenbank. Ein Trace, also eine Spur, ist der ganze direkte azyklische Graph (DAG), respektive Prozess, über alle definierten Arbeitspakate. Eine Darstellung zu Spans und Traces findest du in der Architektur Übersicht. [1,3]
Als Erstes muss natürlich Jaeger in deiner Umgebung installiert werden. Wenn du Kubernetes oder OpenShift benutzt, gibt es bereits fertige Operators oder Helm Charts. Was du einsetzten möchtest, ist dir überlassen. Im Getting Started findest du entsprechende Informationen dazu. Für die lokale Entwicklung oder auch nur zum Ausprobieren gibt es einen all-in-one Docker Container.
Als zweiten Schritt musst du deine Microservice Applikation so konfigurieren, dass Traces und Spans an deine Jaeger Infrastruktur geschickt werden. Für die meisten Frameworks gibt es Bibliotheken, welche einem das Einrichten erleichtern. Für eine Java Spring Boot Applikation genügt es die zwei starter POMs opentracing-spring-jaeger-starter und opentracing-spring-web-starter zum Projekt hinzuzufügen. Danach muss noch konfiguriert werden wohin die Daten geschickt werden sollen. Die Konfiguration und die Details dazu kannst du auf der Github Seite der Java Spring Jaeger Implementation nachschauen.
In unserem Online Shop Beispiel werden die neuen Bestellungen von einem Microservice “order” in einem Kafka Topic gespeichert und von einem zweiten Microservice “stock” wieder gelesen und verarbeitet.
Im folgenden Screenshot des Traces vom Jaeger UI sieht man die beiden Microservices unterschiedlich eingefärbt. Grün für den “order” Microservice und Gelb für den “stock” Microservice.
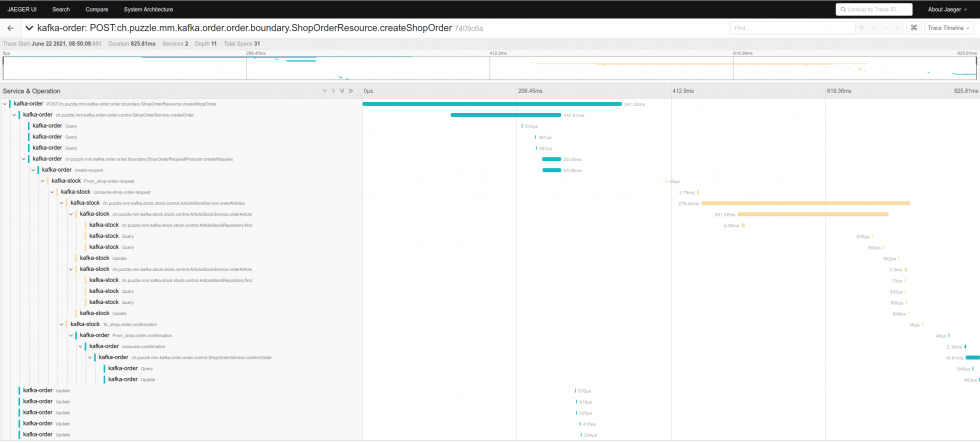
Im oberen Teil ist die Gesamtzeit über beide Services grafisch dargestellt. Auf der linken Seite lassen sich einzelne Spans auswählen um nur diesen Einen zu betrachten oder man wählt keinen Spezifischen aus und alle werden dargestellt, wie es im Screenshot ersichtlich ist. Rechts wird dargestellt, wie lange die Ausführung gedauert hat. Man erkennt ebenfalls, ob eine bestimmte Aktion zu langsam ist. [4]
Wie man selbst Spans erzeugt, zeigen wir dir an einem anderen einfachen Beispiel: [5]
@Autowired
private Tracer tracer;
@GetMapping("/sayHello/{name}")
public String sayHello(@PathVariable String name) {
Span span = tracer.buildSpan("say-hello").start();
try {
Person person = getPerson(name, span);
Map<String, String> fields = new LinkedHashMap<>();
fields.put("name", person.getName());
fields.put("title", person.getTitle());
fields.put("description", person.getDescription());
span.log(fields);
String response = formatGreeting(person, span);
span.setTag("response", response);
return response;
} finally {
span.finish();
}
}
Zuerst wird das Tracer Bean injected. Ein neuer Span wird dann mit tracer.buildSpan("first-span").start(); initialisiert. Im Span selbst kannst du nun Informationen in Form einer Map loggen oder Tags mit spezifischem Inhalt vergeben. Im Beispiel Code werden Attribute der Person geloggt sowie die Antwort der formatGreeting Methode.
Hinweis: Hast du den Span zusätzlich mit span.setTag("error", true) gekennzeichnet, wird dies im UI enstprechend visuell hevorgehoben.
Wichtig: Zum Schluss muss der Span mit der finish(); Methode wieder geschlossen werden.
Wie du die Aufteilung der Spans machst und wie viele Informationen du darin speicherst, bleibt dir überlassen. An dieser Stelle sei noch darauf hingewiesen, dass du allenfalls
a) den Span manuell in einen Thread übergeben musst, falls du beispielsweise mit @Async unterwegs bist (z.B. via AsyncConfigurer) oder b) den Span manuell aus dem Transport Container extrahieren und builden musst: [6]
HttpServletRequestExtractAdapter carrier = new HttpServletRequestExtractAdapter(request); SpanContext parent = tracer.extract(Format.Builtin.HTTP_HEADERS, carrier); Span span = tracer.buildSpan(operationName).asChildOf(parent).start();
Dies siehst du aber in der Regel relativ schnell, wenn der Jaeger Trace nicht zusammenhängend dargestellt wird.
Wenn es um Performance-Aspekte, um die Suche nach Bootlenecks oder aber auch um das schnelle Auffinden von Fehlern in der Prozessierungskette geht, ist Jaeger ein sehr nützliches Tool sowohl für den Betreiber wie auch für den Entwickler.
Wir empfehlen, Jaeger in verteilten Software Architekturen immer einzusetzen. Das Tracing ist normalerweise minimal und kann bei kleinen bis mittleren Applikationen eigentlich immer komplett aktiviert sein. Für Applikationen mit höherem Load lässt sich eine Sampling Rate konfigurieren, welche dann zum Beispiel nur jede 1000ste Anfrage aufzeichnet. [7]
Quellen:
1: https://www.jaegertracing.io/docs/1.23/architecture/
2: https://github.com/opentracing-contrib/java-spring-jaeger
3: https://opentracing.io/docs/overview/spans/
4: https://microservices-lab.k8s.puzzle.ch/docs/04/
5: https://github.com/PacktPublishing/Mastering-Distributed-Tracing/blob/master/Chapter04/java/src/main/java/exercise3a/HelloController.java
6: https://github.com/PacktPublishing/Mastering-Distributed-Tracing/blob/0d1de9a15c5dd7f51e73ce68dd4f3554c15d79a0/Chapter04/java/src/main/java/exercise4b/TracedController.java#L30
7: https://www.jaegertracing.io/docs/1.23/performance-tuning/#adjust-the-sampling-configuration