Einleitung
Seit 2016 setzt Puzzle für Ruby-Applikationen immer stärker auf OpenShift und containerisierte Deployments. Die Technologie darf als produktionsreif bezeichnet werden, best practices zu Tooling und CI/CD-Architekuren etablieren sich aber noch. Dieser Beitrag zeigt, welche Qualitätsmerkmale für eine Lösung zum Deployment und Betrieb von Applikationen auf OpenShift bzw. Kubernetes aus unserer Erfahrung erstrebenswert sind. Er zeigt auch, welche Implementationsansätze wir verfolgen.
Da OpenShift eine Kubernetes-Distribution mit zusätzlichen Features ist, wird der Begriff Kubernetes im folgenden stellvertretend für Kubernetes und OpenShift verwendet.
Die Ops-Mantras: Flexibilität und Nachvollziehbarkeit
Zwei grundsätzliche Erkenntnisse:
Die Anforderungen verschiedener Applikationen (auch mit demselben Tech-Stack) an die Infrastruktur werden auseinanderlaufen. Es ist darum eine gute Idee, Images, CI/CD-Pipelines und Deployment-Konfigurationen nicht vorschnell DRY zu gestalten, sondern angelehnt an die Unix-Philosophie auf kleine Bausteine zu setzen, welche sich vielfältig kombinieren oder ersetzen lassen.
Dinge werden schief gehen. Es lohnt sich deshalb, in CI/CD-Prozessen vorbeugend für den Fehlerfall viele Informationen zu loggen. Logs von CI/CD-Prozessen, Datenbanken und Applikationen sollen immer mit Zeitstempel versehen sein.
Applikationsarchitektur
Applikationen sollen nach den 12 Factor-Prinzipien aufgebaut werden.
Eine Konsequenz daraus: Der Datei-Storage ist gemäss Punkt IV ein backing service. Wenn Benutzer Dateien hochladen, landen diese also am besten in einem object storage (z.B. ein S3-kompatibler Dienst des Cloudanbieters oder eine mitdeployte Minio-Instanz). Dies erleichtert das Teilen von Dateien zwischen Pods (z.B. Background-Workern oder mehreren Webserver-Instanzen). Wer sich auf die ReadWriteMany-Storage des Anbieters verlässt, um Dateien zwischen Pods zu teilen, wird seine Applikation nicht auf jedem Kubernetes-Cluster deployen können.
Deployment
Sane availability
Auf Containerplattformen können unterbruchsfreie Deployments (high availability) realisiert werden. Wer das nicht tut, profitiert vom geringeren Entwicklungsaufwand, da keine unterbruchsfreien Datenmigrationen geschrieben werden müssen. Gleichermassen kann auf Kompatibilitätscode verzichtet werden, da Datenbank und Code immer gleichzeitig aktualisiert werden.
Unsere Kunden und wir leben mit kurzen Ausfällen während Deployments. Mittels wöchentlicher, einstündiger Wartungsfenster, während denen ohne Rücksprache deployt werden kann, vermeiden wir bei jedem Deployment anfallende Koordinationsaufwände zwischen Entwicklung, Kunde und Endkunden.
Woraus ein Deployment besteht
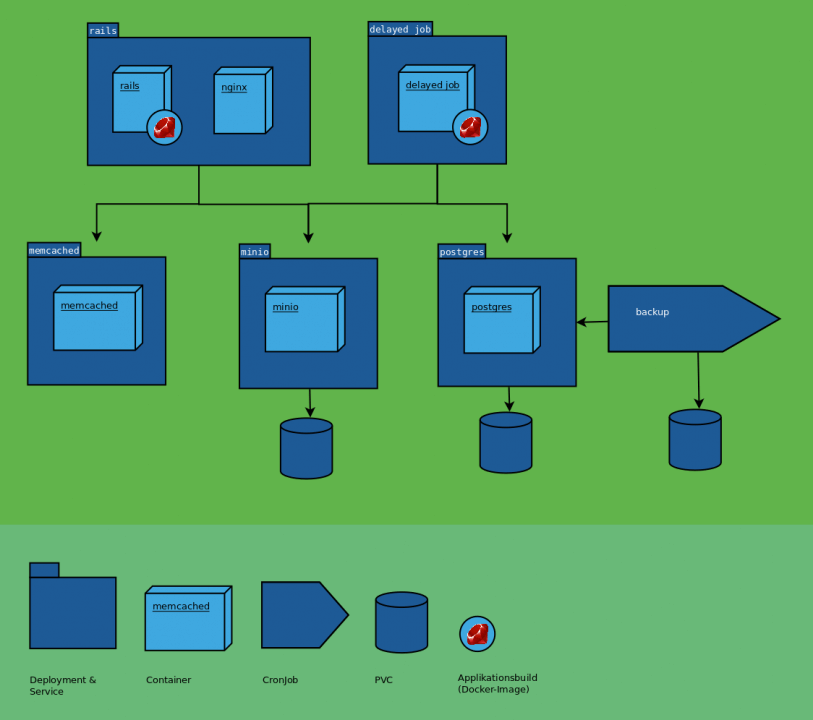
Es gibt viele verschiedene Ansätze um Applikationen auszuliefern. Bei uns wird jede Version eines Applikations-Deployments in einer Kubernetes-Konfiguration beschrieben.
Sie beinhaltet alle Applikationskomponenten, die zu verwendenden Images (und damit Code-Versionen) und die Applikationskonfiguration. Die Kubernetes-Konfiguration ist so gestaltet, dass sie sich ohne weitere Schritte mit oc apply bzw. kubectl apply anwenden lässt (mehr dazu unten).
Health checks
Für jedes Deployment sind readinessProbe und livenessProbe definiert. Liveness-Checks ermöglichen dem Cluster das automatische Neustarten hängender Komponenten, was die „Erste-Hilfe-Massnahmen“ automatisiert. Readiness-Checks sind die Grundlage, um voneinander abhängige Komponenten gestaffelt zu starten.
Abhängigkeiten zwischen Komponenten
Eine Web-Applikation wird meist nicht komplett lauffähig sein, bevor ihre Datenbank läuft. Eventuell muss zusätzlich erst die Datenbank migriert werden, um Schema und Daten in die vom Code erwartete Form zu bringen. Solche Abhängigkeiten sollen in der Kubernetes-Konfiguration und nicht im Deploymentprozess abgebildet sein.
Dazu verwenden wir Init-Container. Das Prinzip ist simpel: Im Init-Container läuft ein Prozess, der solange blockiert, bis die Voraussetzungen zum Start der Applikation gegeben sind. Für Ruby on Rails-Applikationen haben wir zu diesem Zweck das Gem bleib entwickelt. Init-Container können damit auf den Start der Datenbank oder deren Migration warten. Die Migration selbst geschieht entweder in einem weiteren Init-Container oder einem separaten Job.
Kern ist, das der zusammengehörige Applikationscode in einem Schritt deployt werden kann und sich Kubernetes um die Abhängigkeiten und damit um die implizite Reihenfolge kümmert.
Nachvollziehbarkeit
Alle Cluster-Konfigurationen mit Ausnahme der Secrets sind versioniert abgelegt, es werden keine Änderungen an der Konfiguration direkt per CLI oder GUI vorgenommen. Jede Änderung gelangt also via oc apply bzw. oc create auf den Cluster. Diese Disziplin lohnt sich: Es besteht eine zentrale Übersicht über die aktiven Konfigurationen, Konfigurationen verschiedener Umgebungen lassen sich vergleichen und es gibt eine vollständige Änderungshistory.
Konkret legen wir die Umgebungskonfigurationen je Applikation in einem Git-Repository ab. Netter Nebeneffekt: Pull-Requests für Konfigurationsänderungen werden möglich.
Konfigurationsverwaltung
Kubernetes-Konfigurationen werden schnell gross (mehr als 1000 Zeilen) und ähneln sich über Applikationsumgebungen hinweg, aber nicht zwingend über verschiedene Applikationen mit dem selben Technologiestack. Sie sollen deshalb modularisierbar sowie flexibel kombinier- und erweiterbar sein.
Wir erreichen dies mit kustomize. Das Tool ist für Kubernetes gedacht, doch auch OpenShift-Konfigurationen lassen sich gut verwalten (Tipp: Deployments mit k8s-Triggern anstelle von DeploymentConfigs verwenden).
kustomize konzentriert sich alleine auf den Konfigurationsverwaltungsaspekt und überzeugt für kleine Applikationen gleichsam wie für komplexe Setups. Besonders wertvoll ist, dass kustomize bewusst nicht allzu mächtig gestaltet wurde – auch wachsende Konfigurationen bleiben nachvollziehbar.
Die durch kustomize vorausgesetzte Struktur ermöglicht einen Konfigurationslifecycle: Es ist möglich, Änderungen in einer Applikationsumgebung zu testen und danach für alle Umgebungen zu übernehmen oder nachträglich gemeinsame Konfigurationen über Applikationen hinweg zu extrahieren und zu pflegen – inklusive kontrollierter Zurückführung von Änderungen.
Für eine Einführung siehe auch den kustomize-Abschnitt in unserem Kubernetes-Techlab.
Best practices beim Imagebau
Für den sauberen Aufbau eines Images verweise ich auf den tollen Guide von OpenShift.
Wiederverwendbarkeit ist im Kontext von Images ein zweischneidiges Schwert: Wer alle seine Applikationen auf demselben Image basieren lässt, muss bei jeder neuen Anforderung einer seiner Applikationen an das Image sicherstellen, dass auch die restlichen Applikationen noch einwandfrei laufen. Spätestens wenn der Bedarf nach Feature-Switches im geteilten Image entsteht, sollte die Alternative von applikationsspezifischen, aber einfachen und unabhängigen Images genau geprüft werden.
CI/CD
Wohin mit der Komplexität
Es ist eine alte CI/CD-Weisheit: Deployment-Pipelines sollen möglichst „dumm“ sein. Die zu erledigenden Aufgaben, wie etwa Images in der Kubernetes-Konfiguration zu aktualisieren, die Image-Registry zu pflegen oder sicherzustellen, dass ein Deployment erfolgreich war, sind aber nicht trivial.
Wir treffen einige Entscheidungen, um diese Gegensätze unter einen Hut zu bringen und dadurch das CI/CD-Setup wartbar zu halten.
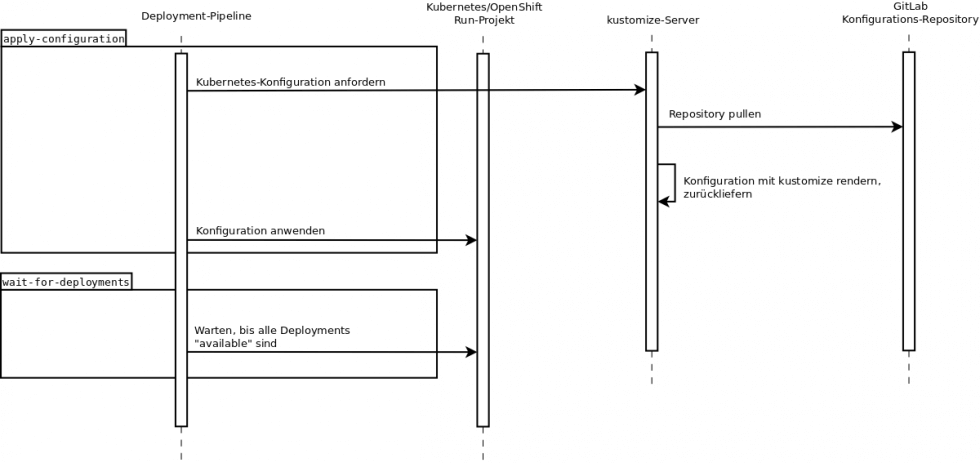
Deployment-Tools schreiben
Komplexere Aufgaben werden durch ein Tool erledigt. Ob ein solches Tool korrekt funktioniert, lässt sich losgelöst von der CI/CD-Pipeline auch auf der Entwicklermaschine verifizieren, was ein schnelles Iterieren bei Entwicklung und Fehlersuche erlaubt.
In unserem Fall delegieren die CI/CD-Pipelines ihre Arbeiten an Ruby-Skripts, welche in Containern auf OpenShift/Kubernetes laufen. Die Skripts bedienen oc bzw. kubectl und parsen deren JSON-Outputs.
Werden diese Logiken dagegen direkt in den CI/CD-Pipelines abgebildet, die ihre Laufzeitumgebung (etwa Jenkins und die entsprechenden Plugins) voraussetzen, wird bei jeder Änderung oder im Fehlerfall ein zeitfressender Versuch-und-Irrtum-Prozess nötig, um die Pipeline abzuändern und zu testen.
Entscheidungen automatisiert testen
Die Deployment-Tools sind nach dem Schema Ausgangsdaten sammeln -> Entscheidung treffen -> Änderungen anwenden geschrieben. Die Entscheidungslogik ist mit geringem Aufwand durch Unit-Tests verifizierbar, das korrekte Zusammenspiel mit den APIs je nach Aufwand/Ertrag-Verhältnis von Hand oder durch Mocks.
Sicherheitspatches
Sicherheitspatches und Container
Das Image, auf welchem ein Applikationsbuild aufbaut, enthält mit den Filesystem der Distribution und den installierten Paketen auch deren Sicherheitslücken. Dieses upstream-Image wird deshalb regelmässig aktualisiert und erfordert anschliessend einen neuen Build und das Deployment des Applikationsimages. Openshift gibt uns dabei hilfreiche Tools wie image change triggers an die Hand.
Auch Images aus externen Quellen wie DockerHub werden regelmässig gepatcht und sollten in der aktuellsten Version verwendet werden.
Deployment und Qualitätssicherung
Bei uns werden gepatchte Images nächtlich erkannt, in die Kubernetes-Konfigration eingepflegt und durch ein Deployment ausgerollt. Eine einzelne Pipeline aktualisiert alle Applikationsumgebungen in Serie, beginnend in der produktionsfernsten Umgebung. Falls ein Deployment scheitert, wird der Prozess abgebrochen, was verhindert, dass die Produktion aufgrund problematischer Sicherheitspatches ausfällt.
Tipp: Ob ein Kubernetes-Deployment mit konfigurierten Health-Checks erfolgreich gestartet wurde, ist den availableReplicas des DeploymentStatus zu entnehmen.
Überwachung
Das Betreiben von Applikationen auf einer Containerplattform bringt den Ops-Teil von DevOps mit sich. Es soll einfach festzustellen sein, ob alle Applikationen laufen und die Backups in Ordnung sind. Wir setzen deshalb zusätzlich zum HTTP-Monitoring und Alerting auf ein Dashboard, welches den Status aller Applikationen auf einen Blick sichtbar macht.
Regelmässig laufende Prozesse überwachen wir mittels eines HTTP-Heartbeat-Systems. Die Eigenimplementation, statuscope, ist open source.

Fazit
Betrieb, Auslieferung und Wartung von Applikationen auf Kubernetes/OpenShift bringen einige Herausforderungen mit sich. Wir haben dafür die umrissenen Lösungen gefunden, mit denen wir zufrieden sind. Im Rahmen unseres Tech-Consultings geben wir das erworbene Wissen gerne weiter und helfen Ihnen, einen sinnvollen Ansatz für Ihr Projekt zu finden. Sie dürfen gerne auf mich zukommen.