OpenStack – Dieser Begriff ist seit längerem in aller Munde. Auch bei Puzzle haben wir uns intensiv mit dieser Technologie auseinandergesetzt.

Interessiert haben uns neben der Frage „Was ist OpenStack und wofür ist es gut?“ auch die OpenStack Distribution „Red Hat Enterprise Linux OpenStack Platform 7“ und deren fortschrittliches Deployment mit „TripleO“.
Was ist OpenStack?
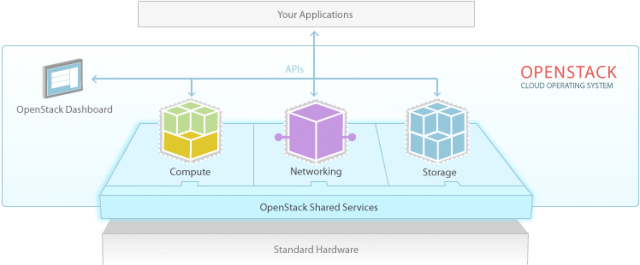
OpenStack ist ein Open-Source Softwareprojekt, welches ursprünglich von der NASA und Rackspace gestartet wurde. Die NASA hatte das Problem, dass jedes Forschungsprojekt jeweils eine eigene Hardware anschaffen und unterhalten musste. Nach Beendigung des Projektes standen die Server dann nutzlos in einer Ecke, während ein anderes Projekt neue Hardware anschaffen musste. Die NASA wollte die verteilte und zur Verfügung stehende Hardware konsolidieren und auf eine standardisierte Art und Weise den Mitarbeitern zur Verfügung stellen. Sie erreichte dies durch das Virtualisieren der Server: Die Benutzer arbeiteten nicht mehr direkt auf physischen Servern, sondern auf virtuellen Maschinen. Dadurch konnten vorhanden physische Server besser ausgelastet werden, da so mehrere virtuelle Maschinen auf einem physischen Server liefen. Jedoch schuf dieser Ansatz auch neue Probleme: Virtuelle Maschinen mussten auch auf eine standardisierte Weise erstellt und gemanaged werden können. Dazu schuf die NASA das Projekt „nova“, welches Compute-Ressourcen verwaltet. Nova ist auch heute noch ein zentraler Bestandteil von OpenStack und ist in der Lage mit allen gängigen Hypervisoren (Xen, KVM, ESXi und HyperV) zusammen zu arbeiten. Die einheitliche Schnittstelle von nova macht es möglich, unabhängig von dem zu Grunde liegenden Hypervisor in kürzester Zeit eine neue virtuelle Maschine zu erstellen.
So wie Nova virtuelle Maschinen verwaltet, so verwaltet „Cinder“ Speicherplatz. „Neutron“ verwaltet die Netzwerk-Infrastruktur und „Keystone“ stellt eine Service-Registry und einen Authentication-Broker zur Verfügung.
Dies wären dann schon die OpenStack-Core-Services:
- Nova
- Cinder
- Neutron
- Keystone
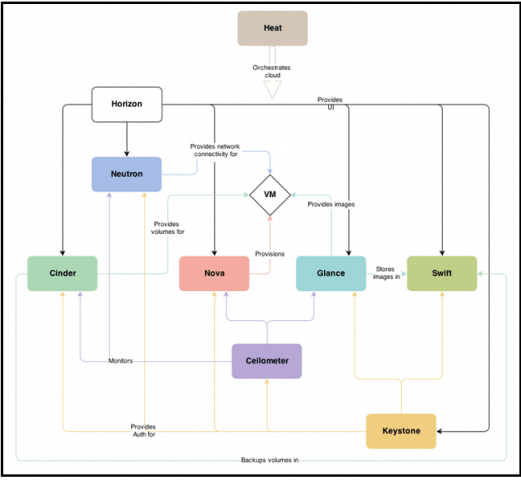
In der Zwischenzeit hat sich rund um OpenStack ein riesiges Ökosystem entwickelt, welches unzählige weitere Services und OpenStack-Projekte hervor gebracht hat, z.B:
- Desginate – DNS as a Service
- Ceilometer – Meetering
- Heat – Cloud Orchestration
- Magnum – Container Integration
- Murano – Software as a Service, Application Catalog
Was kann man mit OpenStack anstellen?
OpenStack bietet einem eine IaaS. IaaS steht für „Infrastructure as a Service“, und bedeutet, dass die zentralen Datacenter-Ressourcen als Services für die Nutzer zur Verfügung stehen. Angesprochen werden diese Services entweder direkt via HTTP oder mit den zur Verfügung stehenden CLI-Clients. Eine IaaS dient als Basis, um die eigentliche Infrastruktur aufzubauen. Da OpenStack eine einheitliche Schnittstelle bietet und sämtliche Funktionalität via Services zur Verfügung gestellt wird, ist es möglich die gewünschte Infrastruktur mittels Text zu beschreiben. Dies ermöglicht es, das moderne Konzept „Infrastructure as Code“ umzusetzen: Sämtliche IT-Infrastruktur wird mittels Code beschrieben und dann auf einer IaaS deployed. Dieses Konzept bietet unter anderem den Vorteil, dass der Code, welcher zur Beschreibung der Infrastruktur verwendet wird, versioniert werden kann. Zudem können so mehrere, identische Umgebungen per Knopfdruck erstellt werden. Dies vereinfacht das Testen und spart zudem Kosten: Die nötige Test-Infrastruktur muss nur solange existieren, wie der Test läuft und kann später wieder automatisch abgebaut werden.
Red Hat Enterprise Linux OpenStack Platform 7
Es gibt viele verschiedene OpenStack Distributionen, welche das „Upstream“ OpenStack paketieren und für eine definierte Zeitspanne Updates und Support anbieten. Bei Puzzle haben wir uns die OpenStack Distribution von Red Hat näher angeschaut. Die OpenStack Platform 7 basiert auf Red Hat Enterprise Linux 7 und wird mittels des „Directors“ installiert. Der „Director“ basiert auf dem OpenStack Projekt „Tuskar“, welches eine GUI für die Installations-Methode „TripleO“ anbietet.
TripleO steht für „OpenStack On OpenStack“ und basiert auf der Idee, OpenStack selbst mit einer OpenStack-Appliance zu installieren. Dazu wird zuerst eine fix-fertige OpenStack Appliance als virtuelle Maschinen gestartet. Dieses OpenStack wird als „Undercloud“ bezeichnet. Die eigentlichen Server für das produktive OpenStack werden nun via PXE mittels eines kleinen Mini-Linux gebootet. Ein Script erstellt ein Inventar der zur Verfügung stehenden Ressourcen (CPU, Storage ect.) und sendet diese Daten an die OpenStack-Appliance (=Director). Aufgrund von vordefinierten Ressourcen-Klassen (=Flavors), werden die entdeckten Server der jeweiligen Rolle zugeteilt: Compute-Node, Storage-Node oder Controller-Node.
Ein Compute-Node hat vor allem viel CPU-Power zu bieten, ein Storage-Node viele Disks und ein Controller-Node dient als Management-Node
Die eigentliche Installation von OpenStack wird via Heat-Templates durchgeführt: Auf der OpenStack-Appliance läuft auch Heat, dies ist der OpenStack Cloud Orchestration Service. Die OpenStack Platform 7 von Red Hat bietet schon Heat-Templates an, um eine OpenStack Umgebung basierend auf Best-Practices aufzusetzen.
Erfahrungen mit „Red Hat Enterprise Linux OpenStack Platform 7“
Das Konzept von Undercloud und Overcloud, welches TripleO zu Grunde liegt, erfordert zuerst etwas Denkakrobatik. Da man ständig mit zwei verschiedenen OpenStack-Installationen arbeitet, braucht man eine Weile, bis man sich zurecht findet. Ist die Undercloud aufgebaut und sind die Heat-Templates für ein Deployment bereit, dann geht alles fast vollautomatisch: Die von Red Hat gelieferten Heat-Templates erstellen automatisch einen 3-Node Pacemaker Cluster für die Controller-Nodes. Als Datenbank-Backend wird sodann auch ein Galera-MySQL Cluster aufgebaut. Als Storage-Backend nutzen wir einen 3-Node Ceph Cluster, welcher auch von den Heat-Templates automatisch konfiguriert wurde.
Das Debuggen der für das Deployment verwendeten Heat-Templates war zuerst etwas umständlich, da die deklarative Syntax eher abstrakt gehalten ist.
Fazit
TripleO ist ein interessanter Ansatz, um OpenStack zu deployen. Für kleinere Umgebungen lohnt sich meiner Meinung nach die zugrunde liegende nötige Denkakrobatik nicht und wird vermutlich eher auf Abneigung stossen. Jedoch kann TripleO seine Stärken bei grossen Deyploments voll ausspielen. Das Skalieren einer OpenStack-Umgebung wird damit zum Kinderspiel. OpenStack ist stetig in Bewegung, so auch die Möglichkeiten, wie man eine OpenStack-Umgebung aufbauen kann. Interessant finde ich vor allem den Ansatz, die OpenStack-Services in Containern zu betreiben. Das Projekt Kolla sieht daher vielversprechend aus. (https://wiki.openstack.org/wiki/Kolla)
Falls Sie selbst OpenStack Luft schnuppern möchten, dann kann ich Ihnen empfehlen. Auch Packstack ist sehr empfehlenswert: Damit erstellen Sie innerhalb von ein paar Stunden ihre eigene All-In-One OpenStack-Installation. )
Salut Puzzle,
es wäre sicher interessant OpenNebula als Alternative für kleiner Installationen anzuschauen.
Freundliche Grüsse,
Nico Schottelius